Will robots ever truly be our “peers” when it comes to peer review?

I had a dream that bothered me. In this dream, I found out that the journal editor had rejected my paper based on an algorithm. In my dream, I was incensed. It made me so irate that I woke up.
Upon waking up, I couldn’t shake the question — would this work? Does it matter? This lead me down the idea that machine learning will likely have an impact on our work, and it’s probably already happening. Time to write something down, before a computer beats me to it.
Peer review in brief
Peer review is a critical aspect of the scholarly process, as (in spirit) it ensures that authors submit quality work for wider dissemination and it proactively opens up ideas for criticism. There are many ways in which peer review could be improved, but that’s a subject for another day.
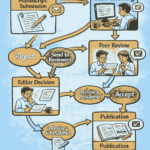
The act of peer review varies from journal to journal but, in general, authors submit their work, the manuscript (and associated documents) are handled by an editor, sent out for peer review, those reports are assessed by the editor, revisions may be sought, and ultimately the article may be published.
Each of those stages involves a human-human interaction, where judgements are made, experiences celebrated, and view-points are sought. The value of peer review is that we are asking our peers to evaluate our work and enable our communication to have more merit. It is far from perfect, it is open to abuse, and it will continually evolve.
The whole endeavour of academic publishing can be a tedious, unrewarding, and time consuming adventure. In our current processes, only the authors are properly rewarded with their articles, which may have been ‘improved’ by the whole process, and are given the gold stamp of peer review. The anonymous peer reviewers are rarely credited. The hard work undertaken by a journal editor will not be rewarded with a Nobel Prize.
Robots as reviewers
Robots are machines that carry out complex tasks automatically. In the realm of peer review, the most likely ‘robots’ will be machine learning algorithms. These algorithms enable difficult tasks to be learnt from vast data sets, and typically it involves derivation of a correlative model through training data. New data can be tested against the correlative model to see how similar (or different) it is to the training data. This testing can be ‘predictive’ in describing how the new data will perform through a process that was used to generate the model, and therefore it can be time consuming but effective in solving problems where a deterministic solution is not easily tractable.
Unfortunately, the nature of machine learning is such that the correlative model is created from the training data and the data reduction is not often human-readable. We are left with a useful, but non-intuitive model, that estimates the likelihood of similarity (or difference) of new information with respect to the pre-existing trained data set.
Machine learning continues to prove extremely useful; it is likely the first step in our march towards artificial intelligence. Machine learning has demonstrated itself with data sets where correlations between similar ‘types’ of information may be weak, such as the language used by junk-mail spammers, or for data sets where the ‘structure’ is not self-evident or obscured by other factors, such as the time of day affecting scene lighting.
In machine learning, we follow an argument that if we train a model with a sufficient amount of input data, we can use this model in a pseudo-predictive manner. The pseudo-predictive nature of this model rests upon our asking of this machine learning system to interpolate correlations between the test data and the reduced model (derived from the training data set).
This interpolation aspect of the machine is a critical benefit and flaw as, for example, it can prove interesting (and uncertain) to ask for an extrapolation query outside of the domain of the training data.
Where is the ‘art’ in artificial intelligence?
While these machine learning algorithms may be called ‘Artificial Intelligence,’ they are only a simulacra of the scientific endeavour. At present, the best algorithms have limited training and experience, as compared to living and breathing scientists.
As scientists, we can cherish our human experiences and training that fall outside the domain of the training set. We recognise the importance and extent of training in the academic context of undergraduate and graduate school, and that science is normally a learning (rather than solution) driven endeavour.
A further complication arises if we consider academic breakthroughs as a stochastic field where ‘bright ideas’ and ‘innovation’ are sacrosanct to moving fields forward. In the realm of peer review, an exciting new paper is likely to be breaking new ground, where it will require extrapolation outside the training data set.
Innovation and impact
Prediction of innovation and impact is a culturally fashionable obsession within the politically inclined scientific class.
To me, innovation is a written-down work that conjures the idea that we will change our practice or our lifestyles. Yet, for delivery of this innovation as ‘impact’ where it affects a class of people (scientists, engineers, policymakers, or the public) we have an uncertain timeline, and hindsight does not give us a view of the unknown unknowns.
Therefore, we concoct a series of proxy metrics which are reflective of our past victories, and view these as an opportunity to provide a crystal ball on the success of each of our next scholarly communications.
These crystal ball approaches have created a few monsters amongst our midst, particularly through the derivation of broken proxy metrics and comparison tools, which are there to enable busy people to sift through complex evaluation processes. However, the utility and efficacy of these proxy metrics (for example the JIF or the associated quality of a ‘name brand journal’) is unfounded and currently subject to review (for example Imperial College has signed DORA).
We can generate a ‘thin end of the wedge’ argument, whereby we envisage machine learning as a path away from engagement in the humanity of good scholarship. Machine learning could promote cookie-cutter approaches to gaming of systems, rather than recognition of true trailblazers or amazing mentors. This would deride all pleasure out of the academic endeavour, limit our ability to inspire, and restrict our ability to solve difficult and unknown problems.
I strongly feel that we must engineer our system of evaluation to have the space and flexibility to evolve; especially because we must steward and encourage good scholarship, reward articulate and effective communication, and provide space for people to evolve the academic landscape.
Bias in training
An algorithm is ‘just’ a fancy implementation of a process. These processes are written in such a way that they can be readily executed, typically using a computer; and in the evolution of computing we can recall that these calculations were first performed by humans.
In writing down a due process, articulated through an algorithm, it is readily possible for us to eliminate subjective bias. We can generate a deterministic outcome from a desired set of inputs, and it can be possible to train out undesired results. This can promote fairness and equality, provided that the bias in establishing the algorithm is well-known.
In the field of machine learning, we establish our algorithms through the use of training data sets and this leads to a standardisation of outcome. This outcome can be fair, in that it treats all the inputs equally. Yet, the reliance of a complex training data set is the method’s strength and weakness. If the training data is not fair, then the model is not fair, and therefore the outputs are unfair. A high profile example of the bias in training systems has been observed when Google’s image tagging algorithm equated black people and gorillas.
As humans, bias is always evident in our systems, whether this is unconscious or conscious. Bias can become embedded through training and systems, and in stochastic and poorly inspected domains these training errors may be more likely. The scientific publishing domain is not open, it is not transparent, and it is subject to the whims of a few very powerful actors.
As a counter-point, we could ask ourselves how much more difficult is it for us to train a legion of peers to move beyond bias? Is it cheaper to build the machines to leap us past our current quagmire?
Luddites and machine learning
With all the buzz about big data and machine learning, it is evident that these tools will have an instrumental impact on our lives.
We can already see this with the simplification of tasks, such as image searching, logistics management, and transportation. In academia, machine learning has a strong foundation in enabling us to reduce the burden of peer review, especially in the management of the formal systems such as in checking plagiarism and similarity.
Even in these limited applications, machine learning should be used to inform, and not make, decisions (i.e. in a supervised mode). Experienced users of plagiarism checkers know how fickle similarity checks may be.
Finally, use of machine learning tools should be declared up front by the journals and their implementation more widely discussed, to ensure that authors can choose and discuss how they wish decisions on the dissemination of their work to be informed.
It is with a slight irony that I sign off this article, knowing that machine learning algorithms will determine if this is of interest to a wider readership.
Dr. Ben Britton is a Senior Lecturer and Royal Academy of Engineering Research Fellow at Imperial College in London. This article was originally published on Dr. Brittion’s Medium blog (available here) and has been republished here with his permission.